A place for API and data pipeline questions.
I’ve done a lot of reporting with the API and DPL, but haven’t pushed much data back into Aspire. Anyone here done that?
Any cool workflow or process automation with the API?
Anyone using low code / no code tools to help utilize the API?
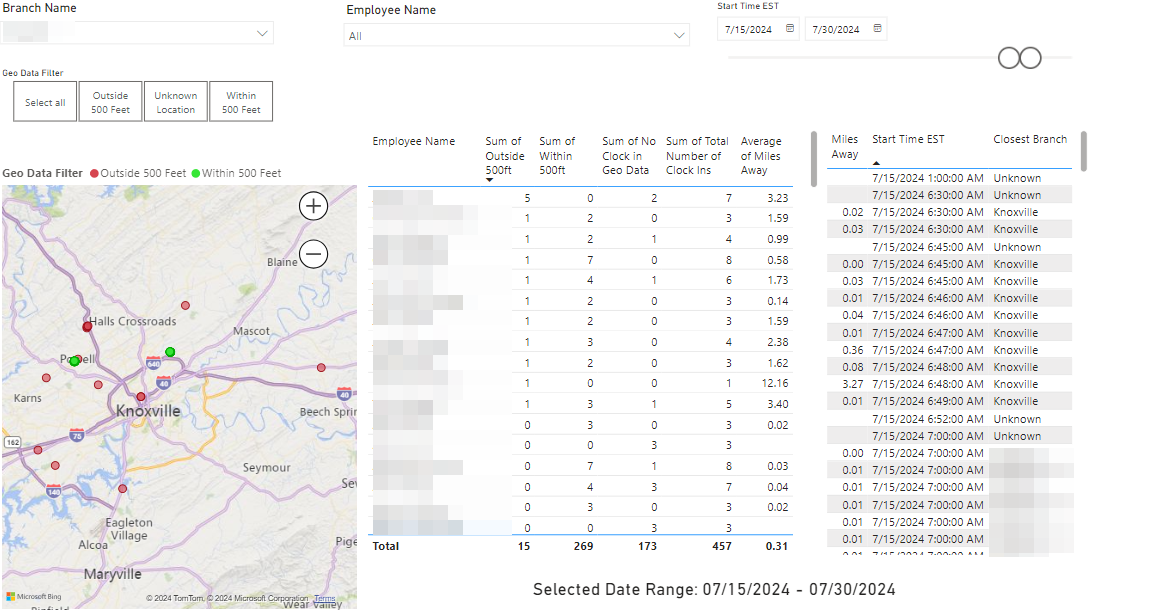
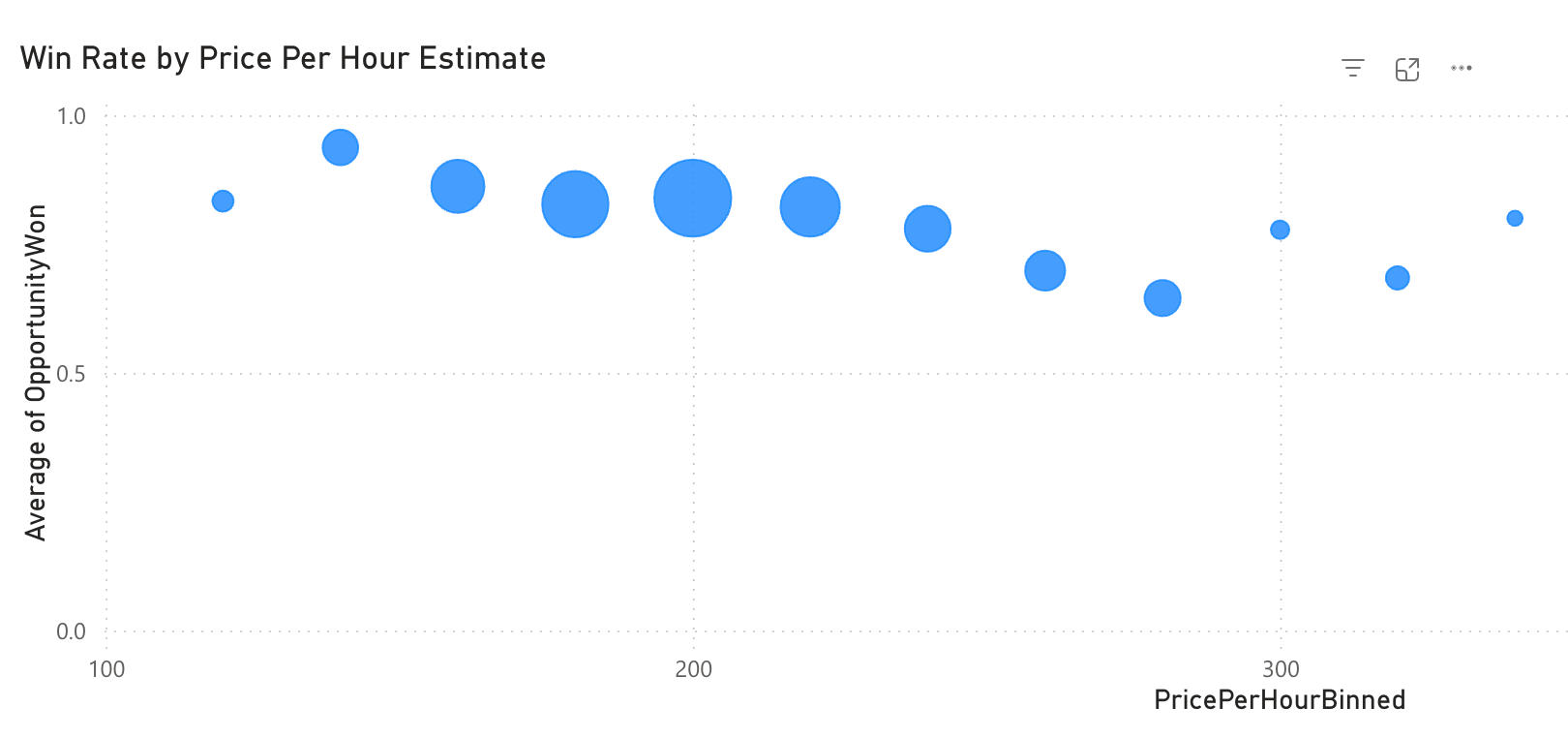
What kind of external reporting are you doing?
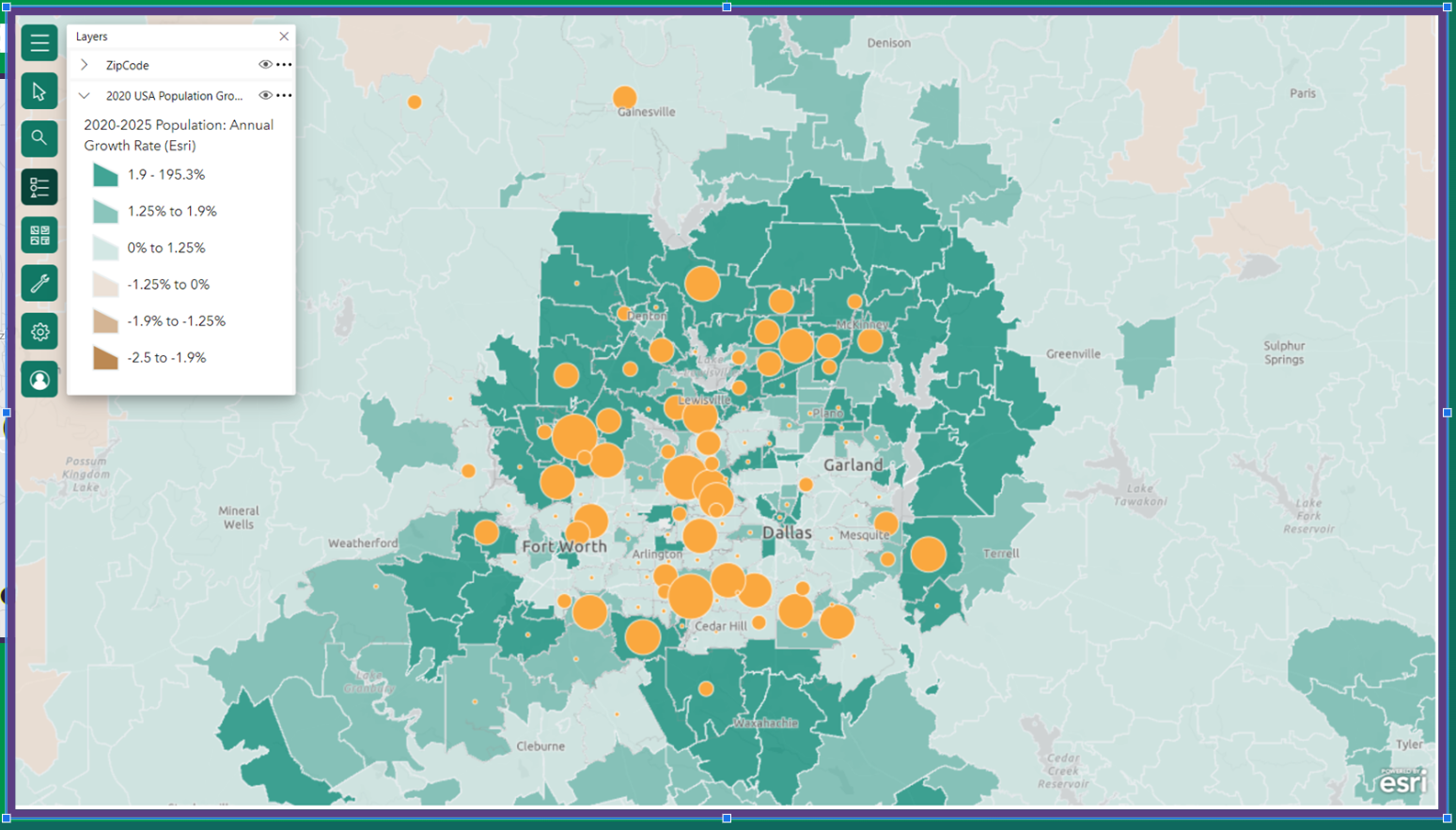
Here’s one we did. It’s an ArcGIS bubble chart in PowerBI showing our Maintenance accounts by Revenue with population growth data overlayed. It helped us plan our next branch location.